Python-OCR — Sistema OCR con Tesseract, Streamlit y Docker
Sistema OCR moderno y escalable para extraer texto de imágenes y PDFs usando Tesseract-OCR. Interfaz web con Streamlit, 100% dockerizado, con arquitectura limpia, principios SOLID y TDD.
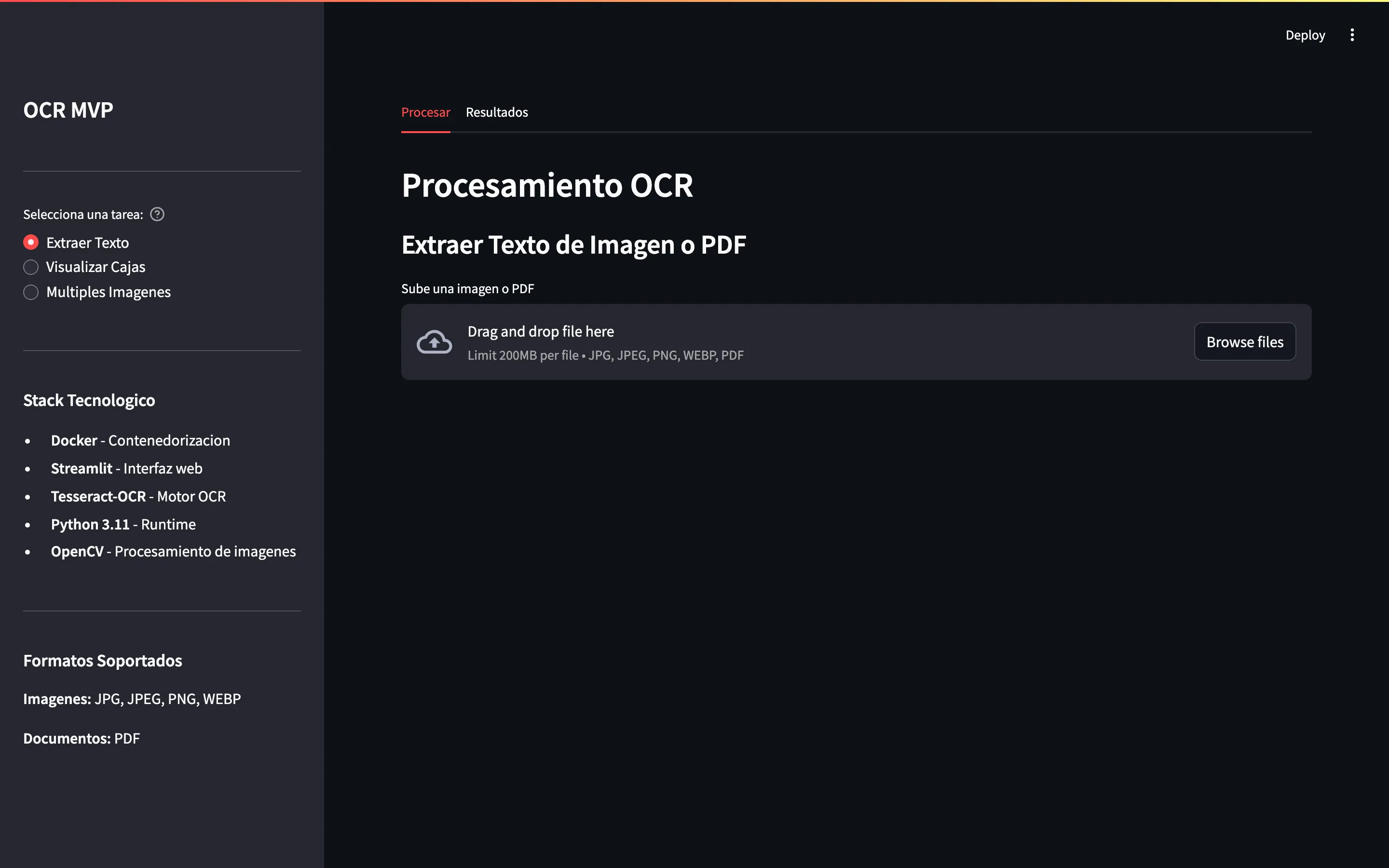
Descripción del proyecto
Python-OCR es un sistema de reconocimiento óptico de caracteres (OCR) moderno y escalable, diseñado con principios de Clean Architecture y Clean Code. Implementa extracción de texto de imágenes y documentos PDF utilizando Tesseract-OCR, con una interfaz web interactiva construida con Streamlit.
El proyecto es 100% dockerizado — cero instalaciones locales requeridas. Solo Docker Desktop y listo.
Características principales
- Arquitectura limpia — Separación clara de responsabilidades entre capas
- Principios SOLID — Código mantenible y extensible
- Test-Driven Development (TDD) — Cobertura de pruebas unitarias con pytest
- Dockerizado — Despliegue consistente sin dependencias locales
- Type Hints — Código Python completamente tipado
- Multi-formato — Soporte para imágenes (JPG, PNG, WEBP) y PDFs
- Extracción de texto con exportación a JSON, Markdown o TXT
- Visualización de cajas — Bounding boxes con niveles de confianza
- Procesamiento por lotes — Múltiples imágenes simultáneamente con tabla resumen
- Hot reload — Cambios en código reflejados automáticamente
Tech Stack
Python & OCR
| Tecnología | Rol |
|---|---|
| Python 3.11 | Lenguaje principal |
| Tesseract-OCR 5.x | Motor de reconocimiento óptico |
| pytesseract | Wrapper Python para Tesseract |
| Streamlit 1.39.0 | Interfaz web interactiva |
| OpenCV (headless) | Procesamiento de imágenes |
| PyMuPDF | Procesamiento de PDFs |
| Pillow | Manipulación de imágenes |
Testing & Calidad
| Tecnología | Rol |
|---|---|
| pytest | Framework de testing (TDD) |
| Black | Formateo de código |
| Ruff | Linter rápido |
| mypy | Verificación estática de tipos |
Infraestructura
| Tecnología | Rol |
|---|---|
| Docker | Containerización (python:3.11-slim) |
| Docker Compose | Orquestación |
| Makefile | Automatización de comandos |
Arquitectura
Diagrama de capas
┌─────────────────────────────────────────────────────┐
│ PRESENTATION │
│ (Streamlit UI) │
│ src/ocr/app.py │
├─────────────────────────────────────────────────────┤
│ BUSINESS LOGIC │
│ (OCR Engine Core) │
│ src/ocr/engine.py │
│ ┌──────────────┬──────────────┬──────────────┐ │
│ │ Extract │ Visualize │ Format │ │
│ │ Methods │ Methods │ Methods │ │
│ └──────────────┴──────────────┴──────────────┘ │
├─────────────────────────────────────────────────────┤
│ INFRASTRUCTURE LAYER │
│ ┌──────────────┬──────────────┬──────────────┐ │
│ │ Tesseract │ OpenCV │ PyMuPDF │ │
│ │ OCR │ Processing │ PDF Parse │ │
│ └──────────────┴──────────────┴──────────────┘ │
└─────────────────────────────────────────────────────┘Estructura del proyecto
python-ocr/
├── src/ocr/
│ ├── engine.py # Motor OCR con Tesseract
│ └── app.py # Aplicación Streamlit
├── tests/
│ ├── conftest.py # Fixtures de pytest
│ └── test_engine.py # Tests unitarios
├── docs/
│ ├── ARCHITECTURE.md # Documentación arquitectura
│ ├── CLEAN_CODE_GUIDE.md
│ └── MACOS_SETUP.md
├── Dockerfile
├── docker-compose.yml
├── Makefile
├── pyproject.toml
└── requirements.txtPatrones de diseño
Static Factory Pattern
OCREngine proporciona métodos estáticos para crear y procesar resultados OCR sin necesidad de instanciar la clase:
class OCREngine:
@staticmethod
def extract_text_and_boxes(image_path: str) -> Dict[str, Any]:
...Facade Pattern
Una interfaz simplificada que oculta la complejidad de pytesseract, OpenCV y PIL:
result = OCREngine.extract_text_and_boxes("image.jpg")Strategy Pattern
Diferentes estrategias para procesar imágenes vs PDFs, manteniendo código desacoplado por tipo de archivo.
Template Method Pattern
Estructura algorítmica definida para procesamiento de PDFs multi-página: convertir → procesar cada página → agregar resultados.
Caching Pattern
Optimización de rendimiento cacheando configuración de Tesseract con @st.cache_data.
Principios SOLID aplicados
| Principio | Implementación |
|---|---|
| SRP | OCREngine solo maneja lógica OCR, app.py solo maneja UI, test_engine.py solo testing |
| OCP | Sistema abierto a extensión (nuevos formatos) sin modificar código existente |
| LSP | Todos los métodos de extracción devuelven el mismo contrato Dict[str, Any] |
| ISP | Métodos pequeños y específicos: extract_text_and_boxes(), visualize_boxes(), generate_markdown() |
| DIP | Dependencia de abstracción pytesseract en lugar de implementación directa de Tesseract |
API del Motor OCR
Extracción de texto
result = OCREngine.extract_text_and_boxes("imagen.jpg")
# {
# "file": "imagen.jpg",
# "full_text": "Texto extraído...",
# "boxes": [{"text": "...", "confidence": 0.95, "bbox": [...]}],
# "total_lines": 10
# }Extracción de PDFs
result = OCREngine.extract_text_from_pdf("documento.pdf")
# Incluye: full_text, boxes con campo "page", total_pagesOtros métodos
visualize_boxes()— Dibuja bounding boxes sobre la imagengenerate_markdown()— Genera resultados en formato Markdowngenerate_plain_text()— Genera texto planopdf_to_images()— Convierte páginas de PDF a imágenes
Clean Code
- Naming conventions —
snake_casepara variables,PascalCasepara clases, verbos descriptivos para funciones - Type Hints obligatorios — Contratos explícitos entre funciones
- Error handling explícito —
try/except/finallycon cleanup de archivos temporales - Principios DRY, YAGNI, KISS — Código reutilizable sin complejidad innecesaria
- Docstrings en formato Google Style
Testing (TDD)
Suite de tests con pytest organizada por funcionalidad:
- TestOCREngineExtraction — Extracción de texto, estructura de resultados
- TestOCREngineFormatters — Generación Markdown y texto plano
- TestOCREngineVisualization — Visualización de bounding boxes
- TestOCREngineBoxStructure — Validación de estructura de datos
make test # Todos los tests
make lint # Linter (ruff)
make format # Formateo (black)Repositorio
🔗 github.com/Vic-Lara-Gilles/Python-OCR
Lenguajes: Python 44.2% · Go 29.6% · JavaScript 7.7% · CSS 6.4%
Licencia: MIT